https://blog.laffitto.xyz乱谈府 ——詹詹碎言2024-10-11T14:43:08.800Zhttps://github.com/jpmonette/feedAspire to inspire until I expire 🎸
也扯淡,也思考,也生活https://blog.laffitto.xyz/images/avatar.pnghttps://blog.laffitto.xyz/favicon.icoAll rights reserved 2024, 乱谈府 ——詹詹碎言<![CDATA[Obsidian好用AI插件]]>https://blog.laffitto.xyz/post/obsidian-hao-yong-ai-cha-jian/2024-10-11T14:40:11.000Z自用好用的AI插件
]]>自用好用的AI插件
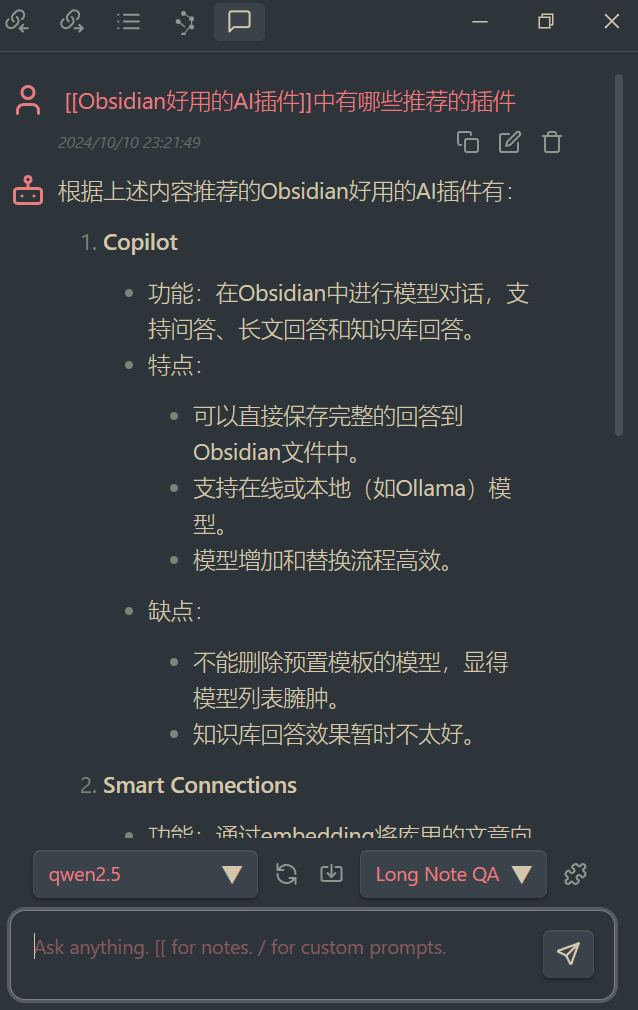
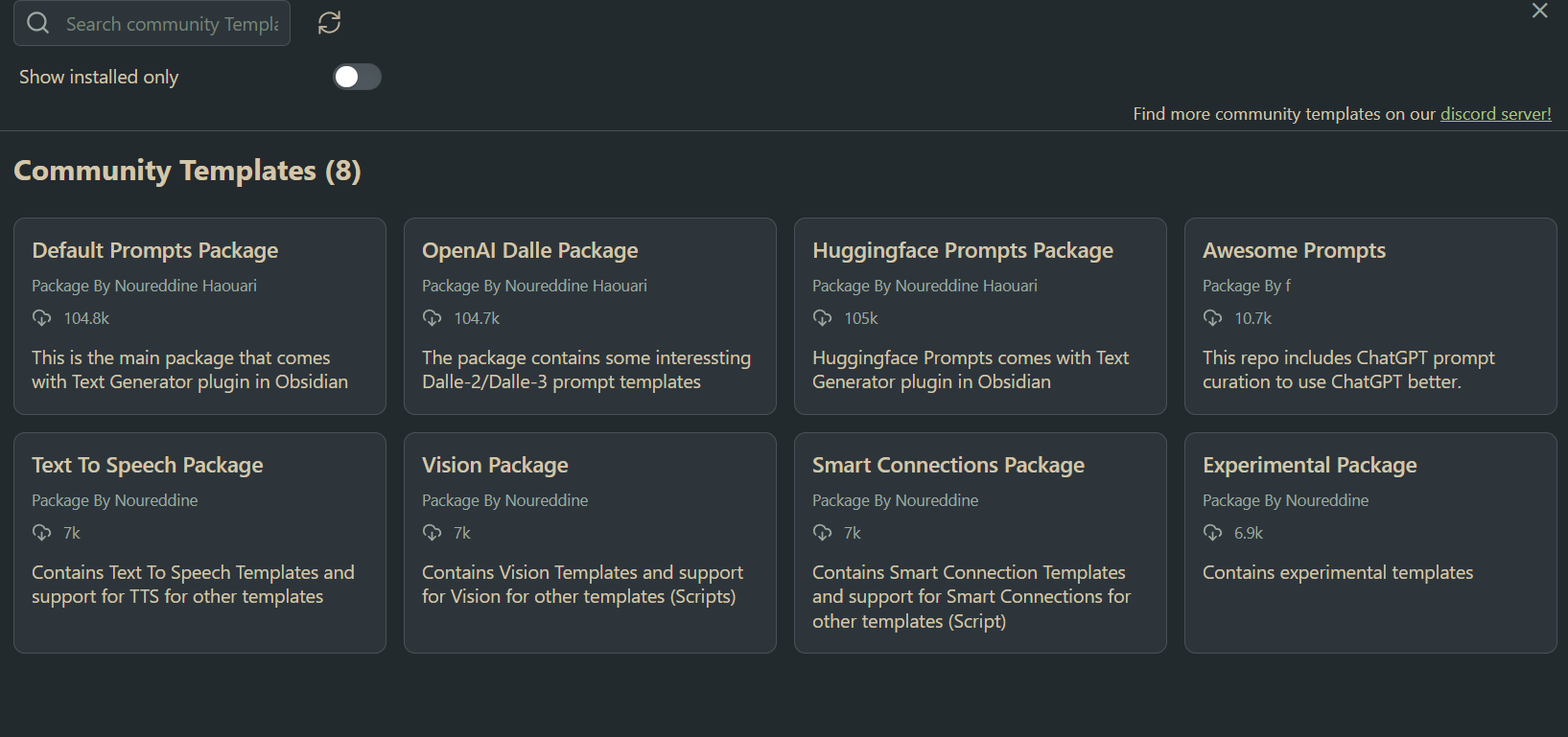
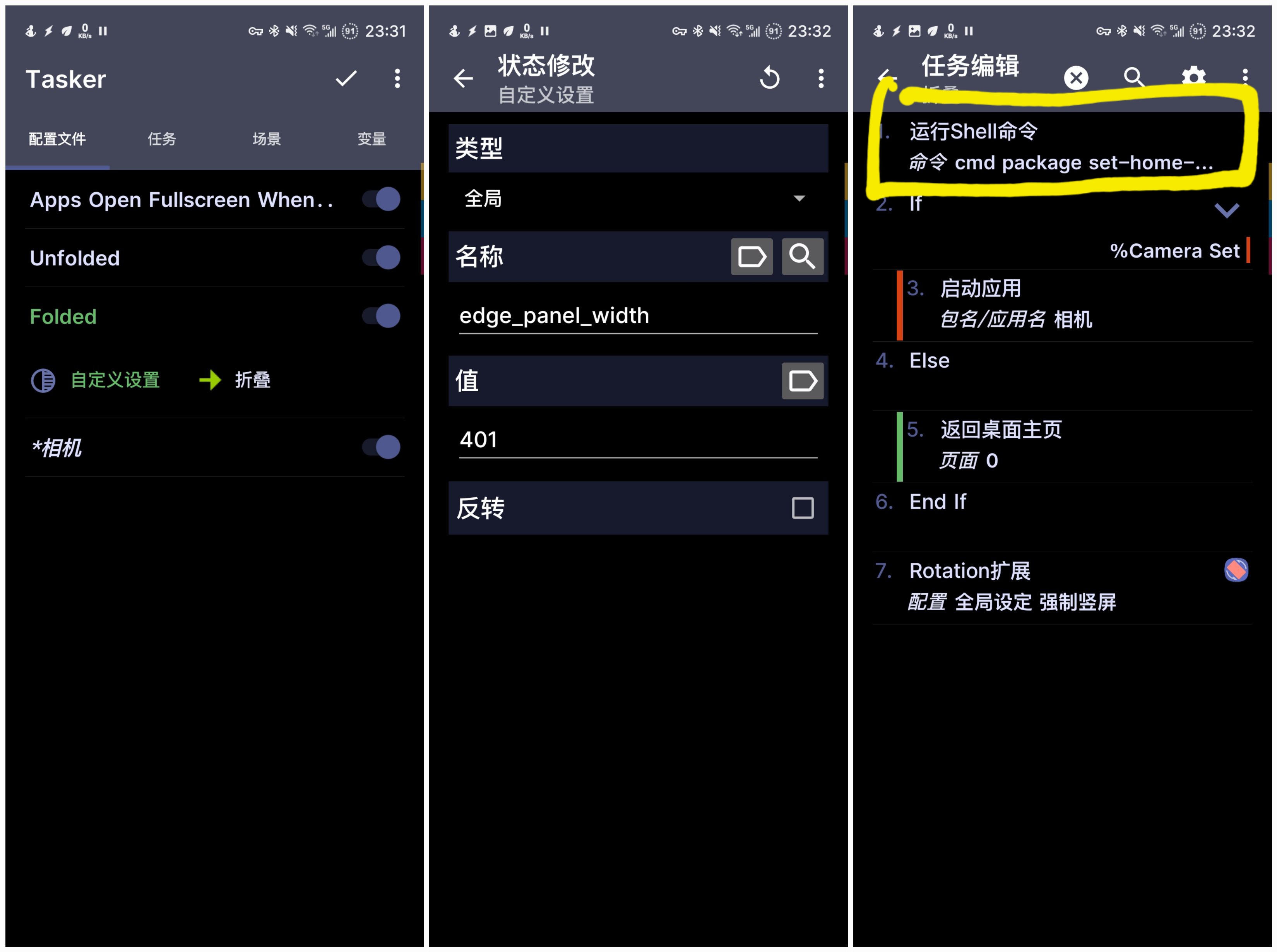
随着这两年 AI 的发展,笔记工具的 AI 属性已然成为一个强大的卖点,NotionAI 的很多功能让人眼馋。好在 Obsidian 有着强大的社区插件支持,在各路大神的加持下,Obsidian 也可以集成众多的 AI 功能。这里推荐几个在目前时间点我用着比较好的插件。其中是否持续更新是一个比较看重的点,有更好的插件也欢迎分享。
剧情上,我个人觉得没啥大问题,黑神话悟空仅仅是在原先西游记的世界观基础上再次创作而已。第一章的贪嗔痴,第二章不可仅听一面之词的道理,第三章黄眉的背道哲学,第四章八戒和蜘蛛精的凄美爱情故事,第五章红孩儿的身世和回忆过往,第六章加上隐藏剧情的铺垫,尽管有些细微的地方可能不同人看会有槽点,但是完全达不到有些 B 站 up 主破口大骂剧情稀烂的程度。那些人拿着西游记的原作去分析原意哲学,大骂游戏科学对其进行的胡编,但是人家只是基于原著的改编了,也不至于如此上纲上线,在我看来像是未免为了突出自己思想观点的不同强行当跳梁小丑罢了。
第二天的主要任务就是逛街。从旺角出发,沿着弥敦道一路向南进发,途径油麻地-佐敦-尖沙咀。路上形形色色的车,形形色色的楼。五彩斑斓的双层巴士,红色鲜艳的小的士。走在香港的街头,路边有繁华的高楼大厦,但同时也有低矮小巷。整体感觉路边乱乱的,但是乱中又透露着秩序,有种矛盾的美感。像是走在一种极度现代与古老的结合体中。
中餐我们找了一家旺角的金华冰厅,在平常的主食基础上,点了菠萝包和西多士。西多士就是炸面包上面加上黄油,不过这一家的西多士有点过于油了,很香但不能够多吃。而且同是港式奶茶,仅仅是冰与热也有很大的区别。
区别于内地的商场,香港地段寸土寸金,有些商场甚至有十几楼高,不过占地面积倒不是很大。从下午走到晚上,一路走到尖沙咀附近,伴随着淅淅沥沥的小雨,再次沿着海滨漫步,星光大道附近有手印长廊,里面有很多明星大导演的手印嵌在其中,还有麦兜可爱的小猪蹄。晚上去一家叫池记的馆子吃的云吞面和艇仔粥,感觉比较正宗,因为云吞面的那个汤够难吃。它艇仔粥的英文够有意思,Congee with pork squid and fish,直观的展示了所有的配料。喝粥是很舒服的,可以消除一定疲惫。这一天走的实在是太累了,从小腿痛到脚后跟。
香港的支付即便是内地过去也不会感觉丝毫不方便,得益于支付宝和微信的普及,你基本可以在任何稍微大一点的地方使用他它们进行支付。再退其次,可以使用 apple 或 google pay 直接开通八达通,作为本地电子化支付的最好选择,无论是地铁公交,还有一些商店,做到了一卡在手,衣食无忧。当然我们还是备了 1000 港币现金的,吃早茶的小馆子没有任何电子支付的手段,手上有点实钱还是安心。
出来后由于没赶上预约米奇妙游童话书内容,先去排队玩了加勒比海盗,不过内容与剧情不能说是一模一样,只能说是毫不相关。结束差不多快2点了,终于去迪士尼小镇炫完了中午饭。15点左右终于看上了预约的米奇妙游童话书,这个类似于舞台剧,整体场景还是十分迷幻的,虚实结合,配合表演者的演唱和舞蹈共同呈现。一开始我还以为是对嘴型,结果原来真的是在唱,Let it go响起时鸡皮疙瘩起立。整体大概30min,质量上乘。