深度学习优化算法总结
基本上是转载了,别人写的很不错,回顾一遍的同时,明白了一点架构,自己也正好拿来应付一下一门比较水的课程的报告😱
在刚开始研究深度学习的时候,学习过许多的优化算法,但是当时仅仅停留在理论了解的部分。同样,在后面进行深度学习程序的测试时,由于较为高度集成的编程环境(例如tensorflow,pytorch等),很多优化算法的部分仅仅停留在用一句简短的命令直接调用相关的优化算法,更多的时候只是无脑的设置为Adam,但对其选择原因和更深层的原理理解都不知不觉进行了忽略。总体来说,就是理论学习和实践环节由于工具的原因出现了较大的脱节,此次正好借助这门课的机会,重新回顾一遍深度学习中常用的优化算法,结合自己之前的笔记和网络上的相关资料对这块重新进行温习总结。
这里引用一则网络上的类比,深度学习的日常就像是炼丹的过程,药材即是数据,各式的炉子即是模型,而火候等就像是类似优化算法一类的变量。因此,优化算法对于整体模型训练的效果是至关重要的。而这其中的优化算法最先想到的应该是SGD(stochastic gradient descent),接着可以大致看成在此基础上渐渐加入一些其他成分,最终构成多种多样的优化算法。大致的发展流程大概是SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam 。
优化算法总体框架
这里先介绍一个看到总结的很好的优化算法的框架,有了这个架构再看算法不免觉得豁然开朗🤠。
首先定义首先定义:待优化参数: ,目标函数: ,初始学习率 。
而后,开始进行迭代优化。在每个epoch :
- 计算目标函数关于当前参数的梯度:
- 根据历史梯度计算一阶动量和二阶动量:
- 计算当前时刻的下降梯度:
- 根据下降梯度进行更新:
其中3和4步骤总体来说都是相同的,差异主要是体现在1和2步骤上,其涉及了梯度的相关计算方法和一二阶动量的融入和表达。
SGD
作为优化算法的鼻祖,SGD的表达形式是最简单的一个,其并未涉及相关动量的概念,因此其可以表示为:
这里带入步骤3,可以发现这里的学习率α是没有变化的,
但是SGD最大的缺点是下降速度慢,而且可能会在沟壑的两边持续震荡,仅停留在一个局部最优点。
SGDM(SGD with Momentum)
到这里,为了解决SGD的震荡问题,引入了动量概念,这里可以理解为加入了惯性。下坡的时候,如果发现是陡坡,那就利用惯性跑的快一些。一阶动量加入,做出了如下改变:
一阶动量是各个时刻梯度方向的指数移动平均值,约等于最近 个时刻的梯度向量和的平均值。
这里t时刻的下降方向是由上一时刻的积累的下降方向和这一时候的梯度共同决定的,且经验上取值为0.9,即占据了更大的比重。
SGD with Nesterov Acceleration
同样SGD会陷入一直被困在局部最优解附近不停震荡的问题。为此,NAG(Nesterov Accelerated Gradient)诞生了,其主要改进在于步骤1,式子变为:
这里不计算当前位置的梯度方向,而是计算如果按照累积动量走了一步后那个时候的下降方向。随后用下一个点的梯度方向,与历史累积动量相结合,计算步骤2中当前时刻的累积动量。
AdaGrad
从这里开始将使用二阶动量,渐渐的“自适应学习率”便慢慢开始出现。SGD及其变种以同样的学习率更新每个参数,但是对于经常更新的参数,我们已经积累了大量关于它的知识,不希望被单个样本影响太大,希望学习速率慢一些;对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本身上多学一些,即学习速率大一些。
所谓二阶动量,即是该维度上所有梯度值的平方和:
结合步骤3的下降梯度可以看出,学习率变成了 。 一般为了避免分母为0,会在分母上加一个小的平滑项。因此 是恒大于0的,而且参数更新越频繁,二阶动量越大,学习率就越小。但是因为 是单调递增的,会使得学习率单调递减至0,可能会使得训练过程提前结束,即便后续还有数据也无法学到必要的知识。
AdaDelta/RMSProp
这里改变一下二阶动量计算方法的策略:不积累全部的历史梯度,而只关注过去一段时间内窗口的下降梯度。
此时二阶积累动量的表达式变为:
这就避免了二阶动量持续累积、导致训练过程提前结束的问题了。通常在步骤三为了避免为0,平方根分母中在实际使用会加入一个很小的值如。
Adam
Adam即是所有前面方法的集大成者,因为它将一阶动量和二阶动量都集成使用了,即Adam——Adaptive + Momentum。
SGD的一阶动量:
加上AdaDelta的二阶动量:
这里附上一张吴恩达老师课程的详细算法实现:

当然这里是二元的情况,且表达符号上也有稍许不同,实际上发现还有一个偏差修正的过程,这是因为初期,都接近于0,明显有点毛病。实际训练经验中。
Nadam
Nadam可以看成Nesterov+Adam
即Adam算法的步骤1变为:
选取方法
对于何种方法适用于何种场合,可以适当使用以下的经验:
-
对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节,而且最好采用默认值
-
SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠
-
如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
-
Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
-
在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果
Adam的问题
综合上面的看来,Adam是一个简单而无脑的算法,直接往里面套就行了。但是实际查阅资料的时候发现,有很多大佬都是抵触Adam的,这主要是由于Adam算法上存在的一些问题。
问题1:可能不收敛
各大算法的学习率是:
其中,SGD没有用到二阶动量,因此学习率是恒定的(实际使用过程中会采用学习率衰减策略,因此学习率递减)。AdaGrad的二阶动量不断累积,单调递增,因此学习率是单调递减的。因此,这两类算法会使得学习率不断递减,最终收敛到0,模型也得以收敛。
但AdaDelta和Adam的二阶动量是固定时间窗口内的累积,随着时间窗口的变化,遇到的数据可能发生巨变,使得 可能会时大时小,不是单调变化。这就可能在训练后期引起学习率的震荡,导致模型无法收敛。
但是也有一个简单修正的方法。由于Adam中的学习率主要是由二阶动量控制的,为了保证算法的收敛,可以对二阶动量的变化进行控制,避免上下波动。
通过这样修改,就保证了 ,从而使得学习率单调递减。
问题2:可能错过全局最优解
深度神经网络往往包含大量的参数,在这样一个维度极高的空间内,非凸的目标函数往往起起伏伏,拥有无数个高地和洼地。有的是高峰,通过引入动量可能很容易越过;但有些是高原,可能探索很多次都出不来,于是停止了训练。
同样为了解决这个问题,可以选用“前期用Adam,享受Adam快速收敛的优势;后期切换到SGD,慢慢寻找最优解的策略”。
一点优化算法的使用技巧
Adam+ SGD 策略
上面说到使用这个方法可以解决Adam可能错过全局最优解的问题。
同样这里要解决两个问题:
- 何时切换优化算法
- 切换算法后的学习率
首先讨论切换算法后的学习率。Adam的下降方向是
而SGD的下降方向是
必定可以分解为所在方向及其正交方向上的两个方向之和,那么其在 方向上的投影就意味着SGD在Adam算法决定的下降方向上前进的距离,而在 的正交方向上的投影是 SGD 在自己选择的修正方向上前进的距离。
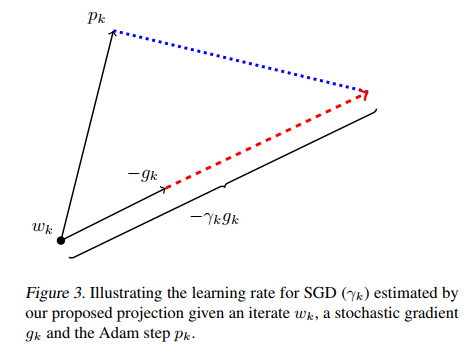
如果SGD要走完Adam未走完的路,那就沿着 方向走一步,而后在沿着其正交方向走相应的一步。
这样我们就知道该如何确定SGD的步长(学习率)了——SGD在Adam下降方向上的正交投影,应该正好等于Adam的下降方向(含步长)。也即:
解这个方程,我们就可以得到接续进行SGD的学习率:
为了减少噪声影响,作者使用移动平均值来修正对学习率的估计:
这里直接复用了Adam的参数。
至于何时进行算法的切换。那就是当 SGD的相应学习率的移动平均值基本不变的时候,即:
. 每次迭代玩都计算一下SGD接班人的相应学习率,如果发现基本稳定了,那就SGD以 为学习率接班前进。
总结
深度学习的优化算法多种多样,但是如何深刻理解,如何使用好它们也是一个需要深究的学问。很多时候看过学过是一回事,而具体实践起来又是另外的一回事,这里借助优化方法的课程回顾了一遍,说实在获得了很多收获。不懂的时候看和懂了一些去回顾都是不一样的感受,可能之后我熟练了再学习一遍时,又会有新的发现。优化算法优化的可能只是些许个参数,然而众多参数的集合却影响了整个模型,模型又可能对应着复杂且重要的实际问题。这就如同蝴蝶效应一般,看似微小的优化却也影响着整体的走势。优化是门学问,需要我们多多去研究体会。